Publications
Filter by type:
 |
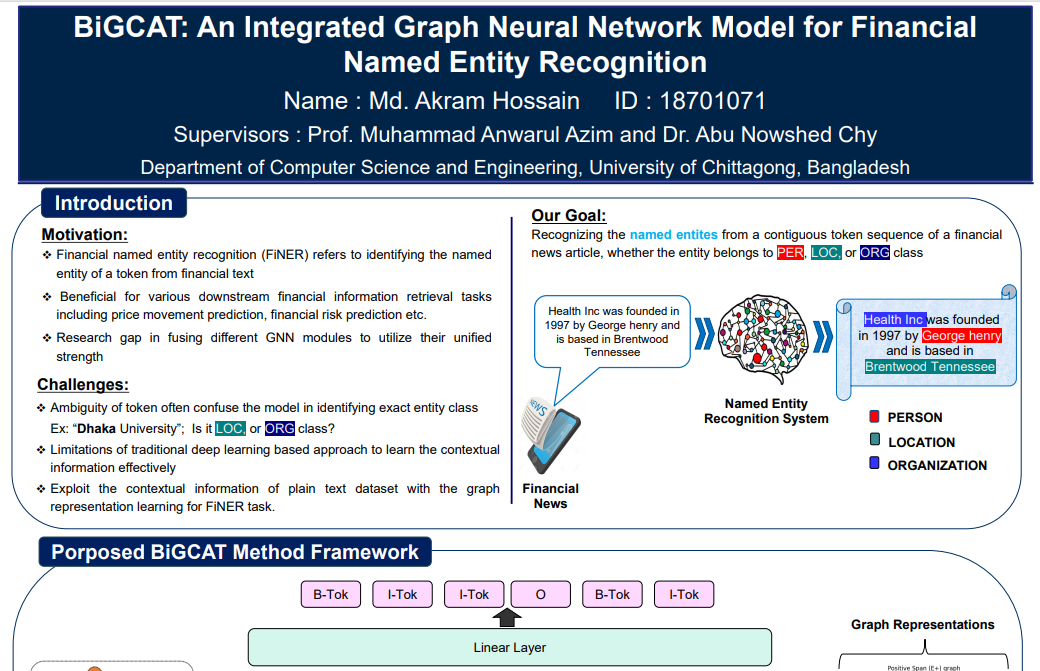
BiGCAT: A Graph-Based Representation Learning Model with LLM Embeddings for Named Entity RecognitionConference PaperRecent Advances in Natural Language Processing (RANLP), 2025.
AbstractNamed entity recognition from financial text is challenging because of word ambiguity, huge quantity of unknown corporation names, and word abbreviation compared to nonfinancial text. However, models often treat named entities in a linear sequence fashion, which might obscure the model’s ability to capture complex hierarchical relationships among the entities. In this paper, we proposed a novel named entity recognition model BiGCAT, which integrates large language model (LLM) embeddings with graph-based representation where the contextual information captured by the language model and graph representation learning can complement each other. The method builds a spanning graph with nodes representing word spans and edges weighted by LLM embeddings, optimized using a combination of graph neural networks, specifically a graph-convolutional network (GCN) and a graph-attention network (GAT). This approach effectively captures the hierarchical dependencies among the spans. Our proposed model outperformed the state-of-the-art by 10% and 18% on the two publicly available datasets FiNER-ORD and FIN, respectively, in terms of weighted F1 score. The code is available at: https://github.com/Akram1871/BiGCAT-RANLP-2025. |
 |
BengaliLCP: A Dataset for Lexical Complexity Prediction in the Bengali Texts.Conference PaperLREC-COOLING, 2024.
AbstractEncountering intricate or ambiguous terms within a sentence produces distress for the reader during comprehension. Lexical Complexity Prediction (LCP) deals with predicting the complexity score of a word or a phrase considering its context. This task poses several challenges including ambiguity, context sensitivity, and subjectivity in perceiving complexity. Despite having 300 million native speakers and ranking as the seventh most spoken language in the world, Bengali falls behind in the research on lexical complexity when compared to other languages. To bridge this gap, we introduce the first annotated Bengali dataset, that assists in performing the task of LCP in this language. Besides, we propose a transformer-based deep neural approach with a pairwise multi-head attention mechanism and LSTM model to predict the lexical complexity of Bengali tokens. The outcomes demonstrate that the proposed neural approach outperformed the existing state-of-the-art models for the Bengali language. |
 |
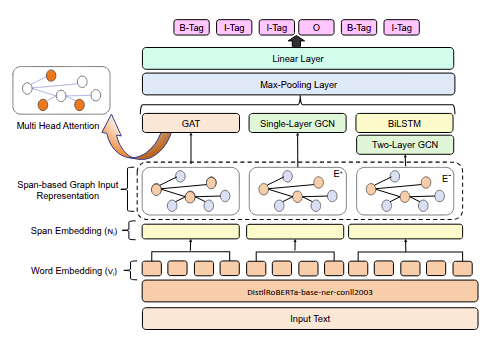
Leveraging Contextual Representations with BiLSTM-based Regressor for Lexical Complexity Prediction.Journal PaperNatural Language Processing Journal, Vol. 5, December 2023.
AbstractLexical complexity prediction (LCP) determines the complexity level of words or phrases in a sentence. LCP has a significant impact on the enhancement of language translations, readability assessment, and text generation. However, the domain-specific technical word, the complex grammatical structure, the polysemy problem, the inter-word relationship, and dependencies make it challenging to determine the complexity of words or phrases. In this paper, we propose an integrated transformer regressor model named ITRM-LCP to estimate the lexical complexity of words and phrases where diverse contextual features are extracted from various transformer models. The transformer models are fine-tuned using the text-pair data. Then, a bidirectional LSTM-based regressor module is plugged on top of each transformer to learn the long-term dependencies and estimate the complexity scores. The predicted scores of each module are then aggregated to determine the final complexity score. We assess our proposed model using two benchmark datasets from shared tasks. Experimental findings demonstrate that our ITRM-LCP model obtains 10.2% and 8.2% improvement on the news and Wikipedia corpus of the CWI-2018 dataset, compared to the top-performing systems (DAT, CAMB, and TMU). Additionally, our ITRM-LCP model surpasses state-of-the-art LCP systems (DeepBlueAI, JUST-BLUE) by 1.5% and 1.34% for single and multi-word LCP tasks defined in the SemEval LCP-2021 task. |
 |
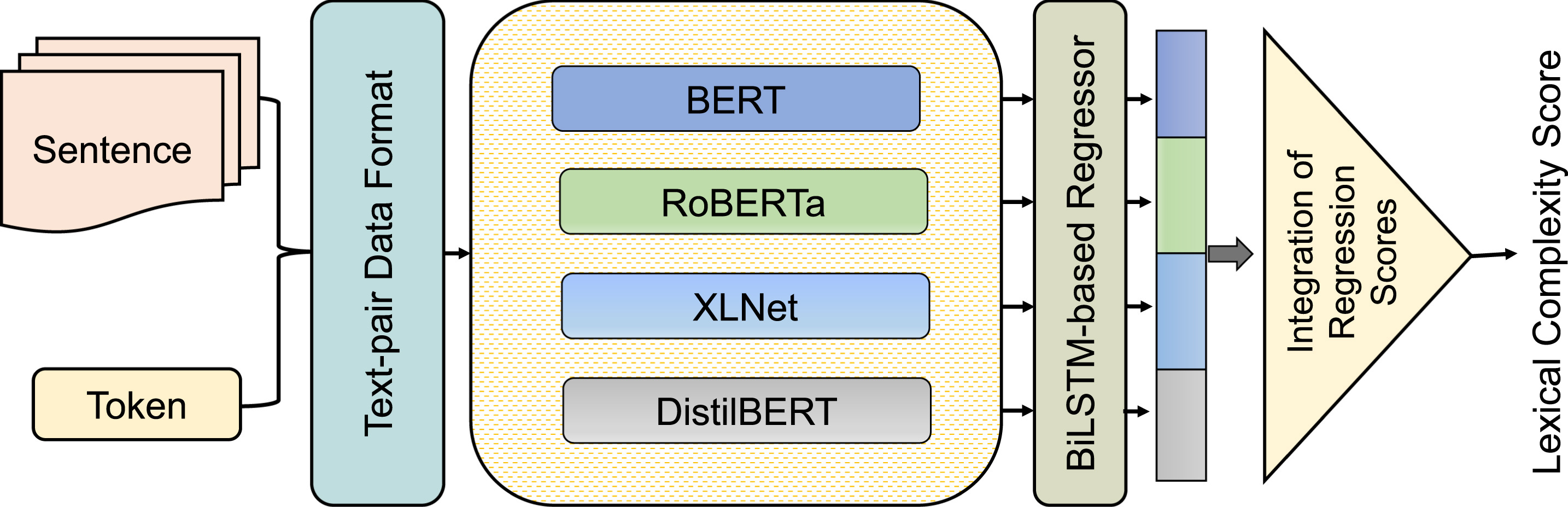
CSECU-DSG at CheckThat! 2023: Transformer-based Fusion Approach for Multimodal and Multigenre Check-Worthiness. [1st place]Workshop PaperCLEF workshop on Check-Worthiness, Subjectivity, Political Bias, Factuality, and Authority of News Articles and Their Sources (CheckThat!), 2023.
AbstractCheck-worthiness is identifying verifiable factual claims present or not in content. It might be beneficial to automatically verify the political discourses, social media posts, and newspaper content. However, the multifaceted nature and hidden meaning of the content make it difficult to automatically identify the factual claims. To address these challenges, CheckThat! 2023 introduced a task to build automatic Check-worthiness classifiers in tweets with multimodal and multigenre settings. This paper presented our participation in CheckThat! 2023 Task 1. We perform fine-tuning on language-specific and vision pretrained transformer models to extract the visual-contextualized or contextualized features representation for the multimodal and multigenre check-worthiness task. We add a BiLSTM layer on top of the contextual features and concatenate it with the other visual or contextualized features to get an enrich unified representation. Later, we employ a multi-sample dropout strategy to predict a more accurate class label. Experimental results show that our proposed method achieved competitive performance among the participants and obtained 1st place in the multimodal Arabic check-worthiness task. |
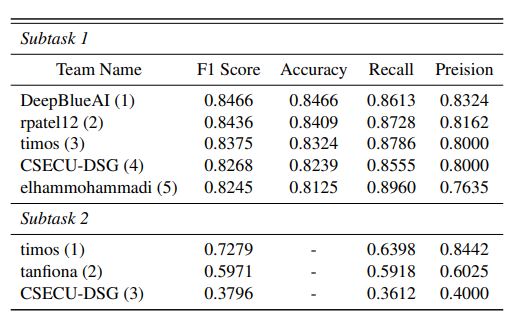 |
CSECU-DSG@ Causal News Corpus 2023: Leveraging RoBERTa and DeBERTa Transformer Model with Contrastive Learning for Causal Event Classification. [3rd place]Workshop PaperCASE@RANLP, 2023.
AbstractCause-effect relationships play a crucial role in human cognition, and distilling cause-effect relations from text helps in ameliorating causal networks for predictive tasks. There are many NLP applications that can benefit from this task, including natural language-based financial forecasting, text summarization, and question-answering. However, due to the lack of syntactic clues, the ambivalent semantic meaning of words, complex sentence structure, and implicit meaning of numerical entities in the text make it one of the challenging tasks in NLP. To address these challenges, CASE-2023 introduced a shared task 3 task focusing on event causality identification with causal news corpus. In this paper, we demonstrate our participant systems for this task. We leverage two transformers models including DeBERTa and Twitter-RoBERTa along with the weighted average fusion technique to tackle the challenges of subtask 1 where we need to identify whether a text belongs to either causal or not. For subtask 2 where we need to identify the cause, effect, and signal tokens from the text, we proposed a unified neural network of DeBERTa and DistilRoBERTa transformer variants with contrastive learning techniques. The experimental results showed that our proposed method achieved competitive performance among the participants’ systems. |
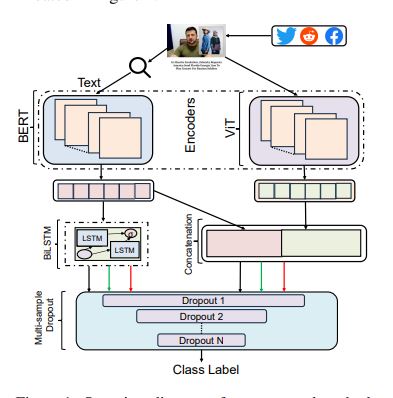 |
CSECU-DSG@ Multimodal Hate Speech Event Detection 2023: Transformer-based Multimodal Hierarchical Fusion Model For Multimodal Hate Speech Detection.Workshop PaperCASE@RANLP, 2023.
AbstractThe emergence of social media and e-commerce platforms enabled the perpetrator to spread negativity and abuse individuals or organisations worldwide rapidly. It is critical to detect hate speech in both visual and textual content so that it may be moderated or excluded from online platforms to keep it sound and safe for users. However, multimodal hate speech detection is a complex and challenging task as people sarcastically present hate speech and different modalities i.e., image and text are involved in their content. This paper describes our participation in the CASE 2023 multimodal hate speech event detection task. In this task, the objective is to automatically detect hate speech and its target from the given text-embedded image. We proposed a transformer-based multimodal hierarchical fusion model to detect hate speech present in the visual content. We jointly fine-tune a language and a vision pre-trained transformer models to extract the visual-contextualized features representation of the text-embedded image. We concatenate these features and fed them to the multi-sample dropout strategy. Moreover, the contextual feature vector is fed into the BiLSTM module and the output of the BiLSTM module also passes into the multi-sample dropout. We employed arithmetic mean fusion to fuse all sample dropout outputs that predict the final label of our proposed method. Experimental results demonstrate that our model obtains competitive performance and ranked 5th among the participants. |
 |
CSECU-DSG at SemEval-2023 Task 4: Fine-tuning DeBERTa Transformer Model with Cross-fold Training and Multi-sample Dropout for Human Values Identification.Workshop PaperSemEval workshop on Multi-lingual Human Value Detection in Texts (ValueEval), 2023.
AbstractHuman values identification from a set of argument is becoming a prominent area of research in argument mining. Among some options, values convey what may be the most desirable and widely accepted answer. The diversity of human beliefs, random texture and implicit meaning within the arguments makes it more difficult to identify human values from the arguments. To address these challenges, SemEval-2023 Task 4 introduced a shared task ValueEval focusing on identifying human values categories based on given arguments. This paper presents our participation in this task where we propose a finetuned DeBERTa transformers-based classification approach to identify the desire human value category. We utilize different training strategy with the finetuned DeBERTa model to enhance contextual representation on this downstream task. Our proposed method achieved competitive performance among the participants’ methods. |
 |
Enhancing the DeBERTa Transformers Model for Classifying Sentences from Biomedical Abstracts. [2nd place]Workshop PaperALTA workshop on automatic sentence classifiers that can map the content of biomedical abstracts into a set of pre-defined categories, which are used for Evidence-Based Medicine (EBM), 2022.
AbstractEvidence-based medicine (EBM) is defined as making clinical decisions about individual patients based on the best available evidence. It is beneficial for making better clinical decisions, caring for patients and providing information about the therapy, prognosis, diagnosis, and other health care and clinical issues. However, it is a challenging task to build an automatic sentence classifier for EBM owing to a lack of clinical context, uncertainty in medical knowledge, difficulty in finding the best evidence, and domain-specific words in the abstract of medical articles. To address these challenges, ALTA 2022 introduced a task to build automatic sentence classifiers for EBM that can map the content of biomedical abstracts into a set of pre-defined categories. This paper presents our participation in this task where we propose a transformers based classification approach to identify the category of the content from biomedical abstracts. We perform fine-tuning on DeBERTa pre-trained transformers model to extract the contextualized features representation. Later, we employ a multi-sample dropout strategy and 5-fold cross fold training to predict more accurate class label. Experimental results show that our proposed method achieved the competitive performance among the participants. |
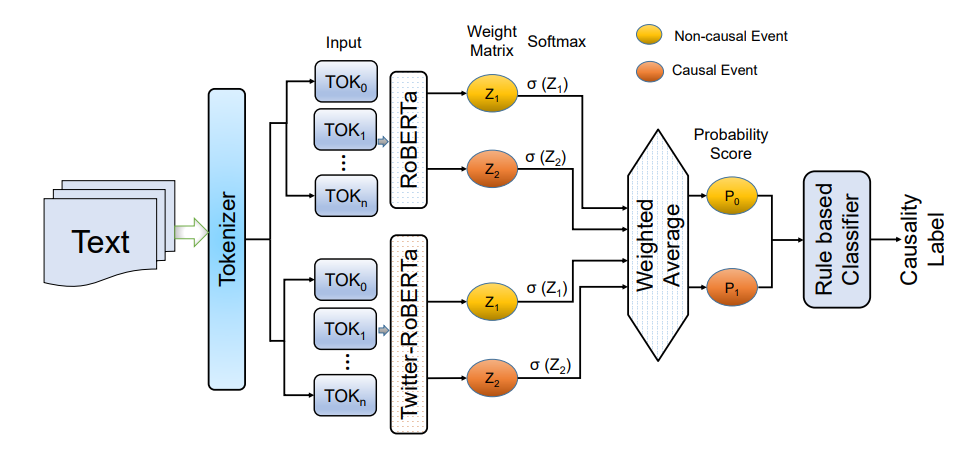 |
CSECU-DSG @ Causal News Corpus 2022: Fusion of RoBERTa Transformers Variants for Causal Event Classification. [1st place]Workshop PaperCASE @ EMNLP | Challenges and Applications of Automated Extraction
of Socio-political Events from Text, 2022.
AbstractIdentifying cause-effect relationships in sentences is one of the formidable tasks to tackle the challenges of inference and understanding of natural language. However, the diversity of word semantics and sentence structure makes it challenging to determine the causal relationship effectively. To address these challenges, CASE-2022 shared task 3 introduced a task focusing on event causality identification with causal news corpus. This paper presents our participation in this task, especially in subtask 1 which is the causal event classification task. To tackle the task challenge, we propose a unified neural model through exploiting two fine-tuned transformer models including RoBERTa and Twitter-RoBERTa. For the score fusion, we combine the prediction scores of each component model using weighted arithmetic mean to generate the probability score for class label identification. The experimental results showed that our proposed method achieved the top performance (ranked 1st) among the participants. |
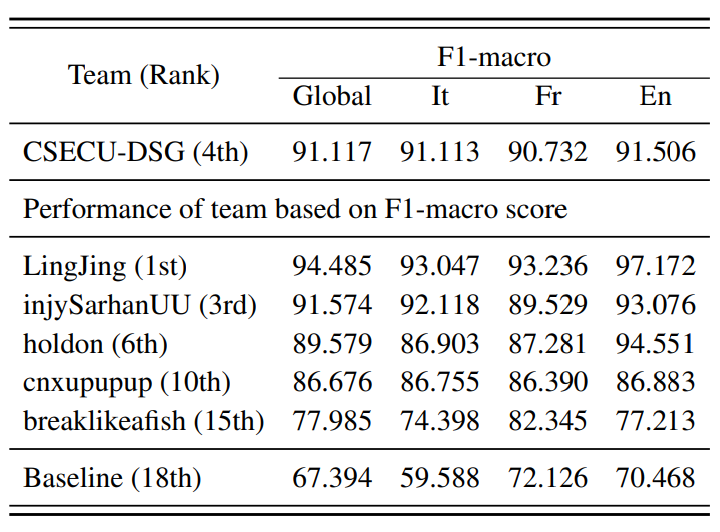 |
CSECU-DSG at SemEval-2022 Task 3: Investigating the Taxonomic Relationship Between Two Arguments using Fusion of Multilingual Transformer Models. [4th place]Workshop PaperSemEval 2022 Task 3: PreTENS | identifying presupposed taxonomies.
AbstractRecognizing lexical relationships between words is one of the formidable tasks in computational linguistics. It plays a vital role in the improvement of various NLP tasks. However, the diversity of word semantics, sentence structure as well as word order information make it challenging to distill the relationship effectively. To address these challenges, SemEval-2022 Task 3 introduced a shared task PreTENS focusing on semantic competence to determine the taxonomic relations between two nominal arguments. This paper presents our participation in this task where we proposed an approach through exploiting an ensemble of multilingual transformer methods. We employed two fine-tuned multilingual transformer models including XLM-RoBERTa and mBERT to train our model. To enhance the performance of individual models, we fuse the predicted probability score of these two models using weighted arithmetic mean to generate a unified probability score. The experimental results showed that our proposed method achieved competitive performance among the participants’ methods. |
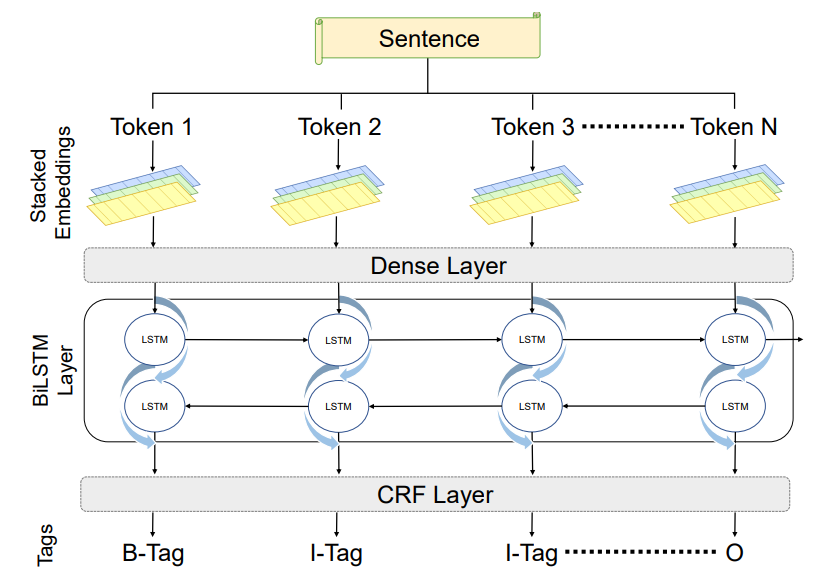 |
CSECU-DSG at SemEval-2022 Task 11: Identifying the Multilingual Complex Named Entity in Text Using Stacked Embeddings and Transformer based Approach.Workshop PaperSemEval 2022 Task 11: MultiCoNER | Multilingual Complex Named Entity Recognition.
AbstractRecognizing complex and ambiguous named entities (NEs) is one of the formidable tasks in the NLP domain. However, the diversity of linguistic constituents, syntactic structure, semantic ambiguity as well as differences from traditional NEs make it challenging to identify the complex NEs. To address these challenges, SemEval-2022 Task 11 introduced a shared task MultiCoNER focusing on complex named entity recognition in multilingual settings. This paper presents our participation in this task where we propose two different approaches including a BiLSTM-CRF model with stacked-embedding strategy and a transformer-based approach. Our proposed method achieved competitive performance among the participants’ methods in a few languages. |
 |
CSECU-DSG at SemEval-2021 Task 1: Fusion of Transformer Models for Lexical Complexity Prediction.Workshop PaperSemEval 2021 Task 1: LCP | Lexical Complexity Prediction.
AbstractLexical complexity prediction (LCP) conveys the anticipation of the complexity level of a token or a set of tokens in a sentence. It plays a vital role in the improvement of various NLP tasks including lexical simplification, translations, and text generation. However, multiple meaning of a word in multiple circumstances, grammatical complex structure, and the mutual dependency of words in a sentence make it difficult to estimate the lexical complexity. To address these challenges, SemEval-2021 Task 1 introduced a shared task focusing on LCP and this paper presents our participation in this task. We proposed a transformer-based approach with sentence pair regression. We employed two fine-tuned transformer models. Including BERT and RoBERTa to train our model and fuse their predicted score to the complexity estimation. Experimental results demonstrate that our proposed method achieved competitive performance compared to the participants’ systems. |
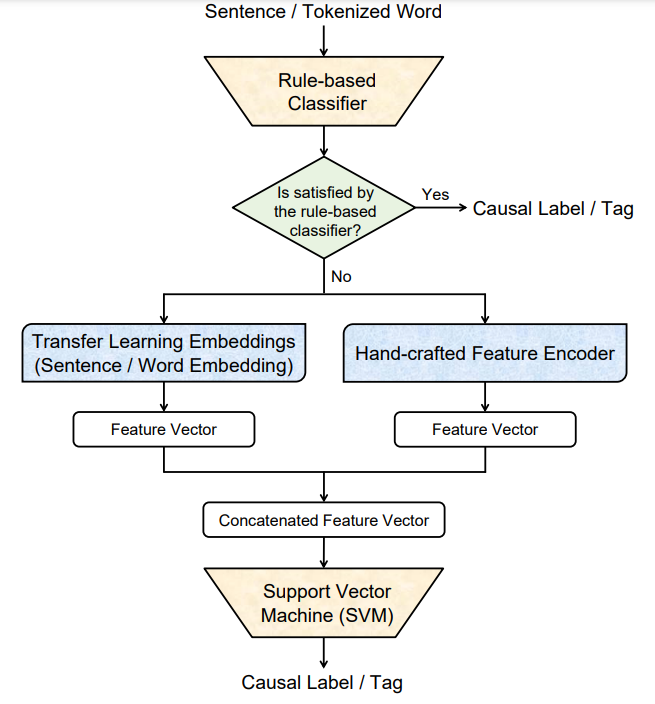 |
Feature Fusion with Hand-crafted and Transfer Learning Embeddings for Cause-Effect Relation Extraction. [1st place]Workshop PaperCEREX @ FIRE | Cause Effect Relation Extraction, ,2020.
AbstractCause-effect relation extraction is the problem of detecting causal relations expressed in a text. The extraction of causal-relations from texts might be beneficial for the improvement of various natural language processing (NLP) tasks including Q/A, text-summarization, opinion mining, and event analysis. However, cause-effect relation in the text is sparse, ambiguous, sometimes implicit, and has a linguistically complex construct. To address these challenges FIRE-2020 introduced a shared task focusing on cause-effect relation extraction (CEREX). We propose a feature based supervised classification model with a naive rule-based classifier. We define a set of rules based on a causal connective dictionary and stop-words. Besides, we use a fusion of hand-crafted features and transfer learning embeddings to train our SVM based supervised classification model. Experimental results exhibit that our proposed method achieved the topnotch performance for cause-effect relation extraction and causal word annotation. |